
RESEARCH, TOOLS, AND PUBLICATIONS
Coverage of Data Explorer (CODEX)
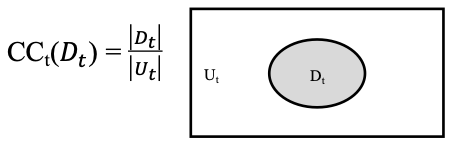
Coverage of Data Explorer, or CODEX, is a Python package that implements data coverage metrics and algorithms
for artificial intelligence (AI)/machine learning (ML) test and evaluation (T&E) applications. CODEX’s metrics
are based on the theory of combinatorial testing (CT) adapted from software testing to AI/ML T&E with a
data-centric focus.
Released to the public in October 2024, CODEX allows a user to assess study a tabular dataset of their choice
in various of modes of exploration that each examine a different aspect of the its contents on a combinatorial level.
Different modes also leverage additional data such as model performance and split configurations to uncover additional
insights on the datasets and its use in machine learning applications.
Transfer Learning in GAN Training
Training effective generative adversarial networks (GANs) from scratch is often a challenge
in terms of training. Not only is the training process costly in time and computational resources,
but datasets of insufficient sizes often encounter training failures.
This project evaluates both the efficacy and efficiency of transfer learning as a viable method
in the realm of generative AI and on limited datasets of images assembled from an open source dataset
such as Instagram. My first discusses these findings in the June 2023 edition of the ITEA Journal of
Test and Evaluation.

PROJECTS
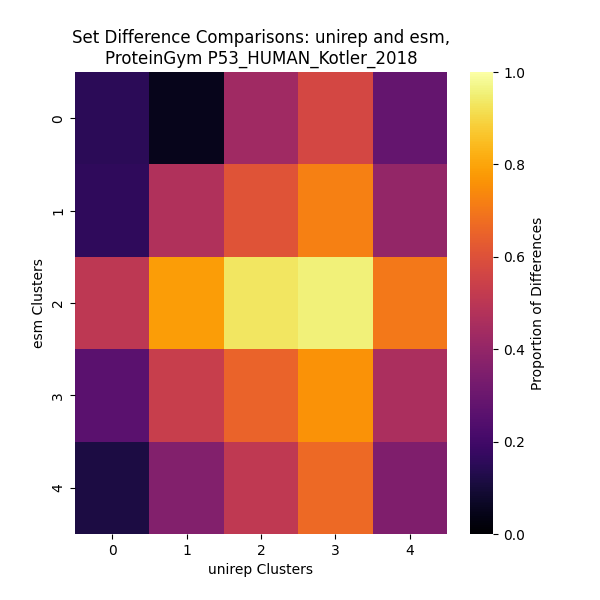
Comparing Latent Space Representations of Protein Sequenceing Models
To understand the special relationship between a protein's amino acid
sequence and its function, today's bioengineers have turned to
machine learning approaches to model these structures accurately. While models exhibit strong
predictive power, their weights and outputs lack explainability, including what, if any,
biological semantics are being learned. This project explores
whether or not latent outputs of protein sequences learned by machine learning models
are similar or different.
This CMDA capstone project was conducted under the sponsorship of the National Institute of Standards
and Technology (NIST) and the instruction of Dr. Peter Tonner, Dr. Angie Patterson, and Dr. Fred Faltin.
Students contributing to this project are Brian Lee, Isabelle Fox, Jonathan Jwa and Joseph Wu.
Game of Life using Message Passing Interface
Precise and large-scale simulations have their own trade-off with
computational limits. Such programs can be processed in parallel,
but just how much added benefit is gained by doing so?
In this project for Computer Science Foundations of CMDA (CMDA3634)
at Virginia Tech, I implement and study the benefits of using
parallel computing through scalability studies.
Alex Ovechkin Goal-Scoring Exploratory Data Analysis and Visualization
Washington Capitals elite Alexander Ovechkin has taken second place for all-time career
goals scored in NHL history and shows no sign of slowing down. Although it is known he has
a talent for scoring goals, game data suggests that he is in a league of his own entirely.
This being one of my earliest personal projects, I use basic data preprocessing and statistical methods
to extract characteristics and patterns in Ovechkin's goal-scoring. They are subsequently
used in striking and creative visualizations to easily convey his unmatched proficency when
compared to his peers leaguewide.

LEADERSHIP
Computational Modeling and Data Analytics Club
Throughout my time at Virginia Tech, I have supported the advancement
of data analysis and data literacy as skills necessary for a world
depending on its insights. One opportunity I saw was to get the CMDA
club back on track. In my two years as president and officer, I tried
to create new opportunities and spaces for CMDA students to practice
their skills and learn from more experienced individuals.
Data competitions hosted by the club have been the primary way that members were able
to get practical experience working with data outside of the classroom.
The CMDA Club is proud to have hosted fall and American Statistical Association
(ASA) Datafest data competitions. In addition to data competitions, the club has seen
interesting workshops exploring more niche topics in the data science world.
